
Teaching LLMs
Wouldn't it be great if LLMs learned from user feedback?

“2025 is gonna be the year of agents”. My ass.
2025 was the year when most AI companies (including the one where I was chief AI scientist) tried to build useful systems with AI, but mostly failed.
I worked at a french legal tech and we tried to automate the tedious part of notaries jobs. We built a chatbot (soooo 2024, but wait, it was an agentic chatbot, and there was a fair bit of engineering in it), and gave it to notaries to test.
They kind of liked it.
But like any other chatbot, it doesn’t learn from user feedback. Which is infuriating.
When you tell it “you failed. Next time, you should do THIS instead”, it says “sure, I won’t make the same mistake twice”. But it eventually does.
Most modern chatbots have a “memory” function that’s supposed to help with that, but it mostly sucks.
Here, I’d like to present a technical idea that I haven’t had time to test, but that I think would have a decent chance of making LLMs able to learn on the fly. It’s based on privileged information, distillation and prefix tuning (one of the best papers I’ve ever read, btw).
The feedback doom loop: you don’t want to teach a student who won’t learn
Do you ever downvote/upvote a ChatGPT response? I guess not. Because it’s useless, as ChatGPT won’t take the feedback into account until it’s too late for you to care.
Big AI firms would love to have conversation data on domains where LLMs typically fail. But they don’t get much of it, because users get a better and better sense of what LLMs fail at, and don’t give them tasks related to these domains (let alone give any feedback).
So, there’s a negative feedback loop:
LLMs suck at tasks where training data is sparse. => Users don’t engage with them on these tasks, and don’t give feedback anyway. => Training data for these tasks remains sparse.
What if, instead, you knew ChatGPT would improve right away based on user feedback? And not only temporarily, but across different chats?
I guess you'd be willing to take a bit of time to tell it that “when writing an email to <Polish customer who gets offended by elementary politeness>@big-steel.pl, always use ‘get lost’ instead of ‘kind regards’”.
So, the vicious circle would break: the ability of the LLM to learn would make giving feedback directly profitable to the user.
Okay, but how do you teach an LLM?
Here’s the complete workflow that I’d suggest:
When a user is dissatisfied with the LLM’s actions, they downvote its response.
They then give constructive feedback.
If the LLM gets it right with the additional feedback, the user upvotes the feedback-enhanced response. Else, back to 2.
The constructive feedback is distilled into a few learned tokens or prefixes at the beginning of the context window. It’s the obviously difficult part, so it’s detailed in the next section.
Whenever the user starts a new conversation, the learned tokens/prefixes are loaded and prepended to the system prompt.
How do you distill feedback into a few learned tokens/prefixes?
You may think that we don’t need to. Why not just updating the model to increase its likelihood of outputting the right answer?
What we don’t want: Normal (LoRA) fine-tuning
When you want to fine-tune an LLM, you usually give it a bunch of pairs of (prompt, desired output). Then, it’s trained on the normal next-token prediction task: the backpropagated loss is usually -sum(log(prob)), prob being the probability that the model assigned to the ground truth token (the one that is actually part of the desired output).
Some guys observed that the difference matrices (let’s call them ΔW) between the weight matrices before and after fine-tuning usually have a high condition number (ratio between largest and smallest singular values), meaning that they can be well approximated by low rank matrices.
So, these guys figured out that it’d be much more efficient to train ΔW as a low rank approximation:
Where:
r is usually around 8 or 16, while d or k are closer to 8192 (Llama 3 70B for example).
It makes training much more parameter efficient.
Still, if you serve each user a different model, you get into some really hard infrastructure challenges. Batching user requests to process them in parallel (as is absolutely necessary to use GPUs efficiently) becomes quite difficult, because they all use different adapters (ΔW set of matrices). It’s partially solved, but it’s still a bit of a nightmare.
How about using a nice feature of transformer networks that allows them to somewhat learn without necessarily changing their weights?
What we could test: Prefix/prompt tuning
When you first discover Machine Learning, it’s common to think “wait a minute, how about we make a model that updates its weights based on its inputs. Like, on the fly, not just during training. Wouldn’t it be cool? It would make the model able to learn much deeper patterns”.
Turns out, the idea of having a network update its weights based on its inputs is called a hypernetwork, and it’s equivalent to having a network that’s highly non-linear on its inputs.
Transformers are just that.
Meaning that adding1 a bias to the inputs (like, say, adding a few tokens before a prompt, which is exactly the purpose of a system prompt) can really change the behavior of an LLM.
So, instead of backpropagating the loss to update the weights of the model, we may get away with backpropagating it to update a few learned tokens (invisible to the user) that will be prepended to the context.
Like an invisible and learned system prompt written in the continuous embedding space rather than the discrete token space. This is the concept of prompt/prefix learning.
As for the “fine-tuning” data, it would comprise pairs of (original_user_prompt, llm_generated_answer_after_user_feedback).
Now, let’s see why this technique is likely to be quite data-efficient, and how to make it even more so.
Data efficiency is key: this is where distillation and prefix-tuning’s lack of expressivity can help.
Pretraining necessitates billions of examples. Fine-tuning necessitates hundreds, at the very least. How could we teach an LLM from only ONE human feedback?
Here’s where expressivity and distillation come into play. Let’s dive quite deep into both concepts.
Expressivity
If an LLM sucks at a certain language, no amount of prompt engineering will make it able to master it. You need at least high-rank Parameter-Efficient Fine-Tuning (through LoRA) for that. In fact, you’ll probably be better off with a full fine-tuning of the model at that point.
On the other hand, prompt engineering is sufficient to tell a model to use such and such library when coding, or to change its tone.
More rigorously, full fine-tuning is more expressive than prompt engineering. The expressivity of a “steering” method basically defines how powerful it is: how much it can change the transfer function of a Neural Net.
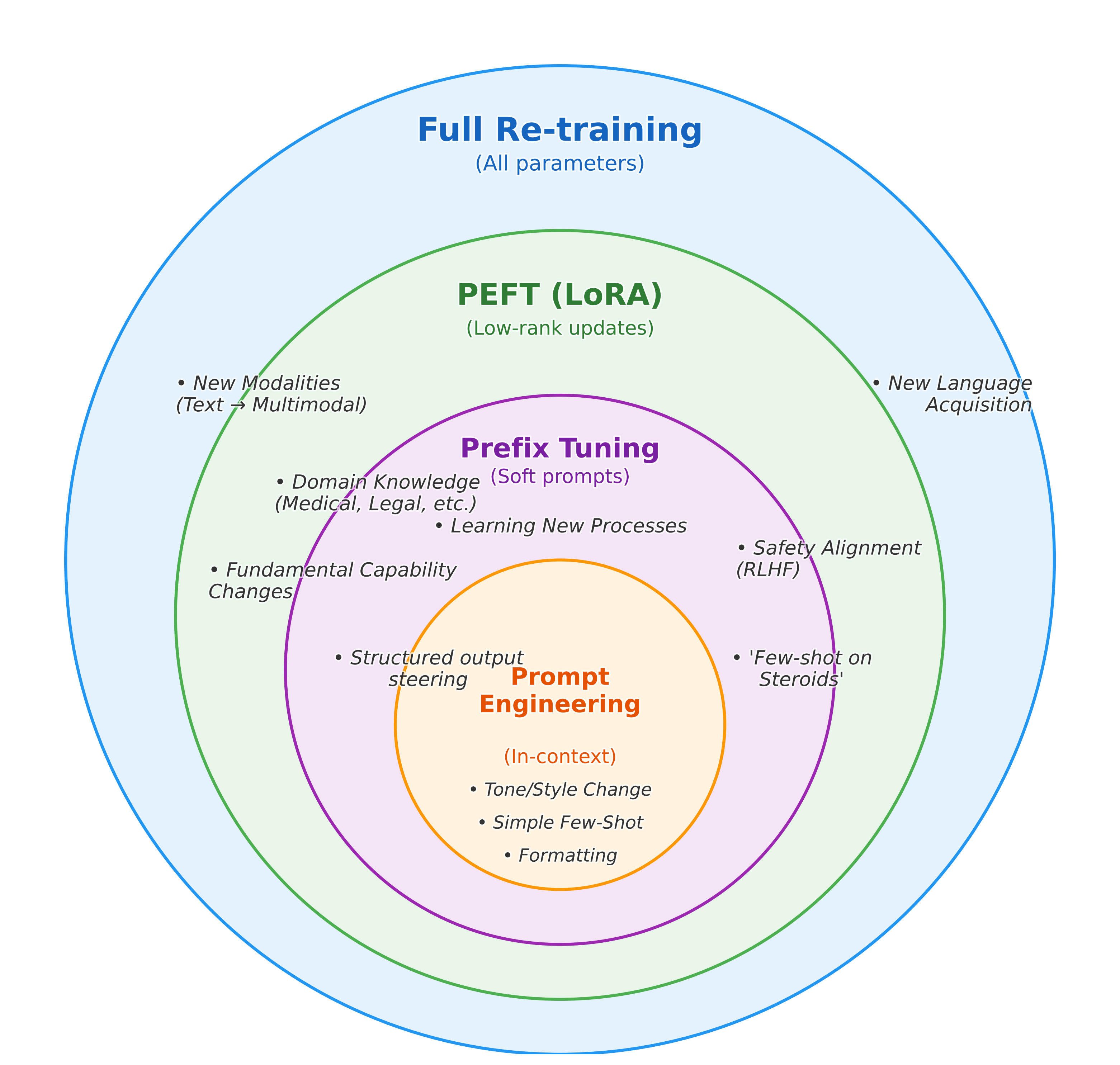
Whatever you can do with prompt engineering, you can also do with full fine-tuning, but you’d need a shitload of examples to constrain the search space enough.
That’s when we run into the expressivity vs. sample efficiency tradeoff, which is just a particular case of the bias-variance tradeoff. I’ve coded a toy demonstration of it that you can check in the annex.
When a training method (or a model architecture) is able to fit a very large class of functions, it needs a very large dataset to define what, precisely, the function to fit is.
It’s a bit reminiscent of the “you need as many linear equations as there are dimensions in a vector space to define a point in it”.
System prompt (or prefix) tokens can only bias the attention scores without changing their order, while LoRA can completely change the relative importance of token-to-token interaction.
Meaning that, if interaction(token1, token2) > interaction(token2, token3) in a certain attention head of the base model, this relationship will always stay true regardless of the number of prefix tokens you add. On the other hand, a LoRA fine-tuning could reverse the order.
This is why, from a mathematical perspective, prompt engineering will never replace a full fine-tuning on a few billion tokens.
But in our case, I think prefix tuning is the sweet spot: more expressive than prompt engineering (not constrained by the discrete space of real-world tokens), yet still very sample-efficient. How can we make it even more so?
Distilling user feedback into learned tokens
Usually, when you fine-tune a model on real data, the loss function compares the next token probability distribution as predicted by the model with the ground-truth distribution (which obviously is one-hot). It computes the cross-entropy of that distribution, which handily simplifies as -log(probability).
Indeed, you’ll never find a text where the author gives a quantified insight into their hesitation when choosing their words. So real-world ground truth will always be a one-hot.
When you distill a teacher model into a student model, though, you can see the full output probability distribution of the teacher. And it carries much more information than the one-hot ground truth distribution2. So, you train the student model on the output distribution of the teacher.
It’s much more sample-efficient, and plainly better in terms of final loss on the real-world dataset, as the teacher’s outputs are less noisy than real-world data.
So, what about distilling the base model + user feedback into the base model + prefix tokens?
It would basically amount to compressing the user feedback. As the number of corrections grows, compression becomes increasingly interesting:
When user feedback gets a bit contradictory (like “in case A, do B, but in (the similar) case C, do D”), prefix tuning can help a lot, by basically finding the best theoretical prompt that allows this.
It helps limit the context size.
I think the fact that both prefix tuning and prompt engineering can only bias attention scores without changing their order3 would even make it possible to use intermediate activations in the distillation’s loss function.
Like, using a kind of regularization term on the MSE of each attention layer's activations.
But prefix-tuning won’t be sufficient for all use cases
True. At some point, the distance between the base model and the feedback-enhanced one will likely become too large for prefix-tuning to handle.
But if models are made a little more able to learn, maybe users will bother to teach them.
The learning doesn’t need to be perfect, just good enough for AI labs to gather feedback and training data on domains that are at the frontier of what LLMs can do. Then, pretraining can do the job.
That’s all I had to say. Writing this blog post took longer than it would have taken me to test this idea with Gemma 270M on my Mac, but I think it was more fun.
Conclusions, TL;DR
Current LLM memory is broken: users have no incentive to give feedback, because they don’t want to waste time teaching a student that won’t learn.
I propose distilling user corrections into learned prefix tokens. More expressive than prompt engineering, more sample-efficient than LoRA, and deployable without per-user model serving.
This reverses the negative feedback loop: if the LLM visibly learns, users will actually bother to teach it.
Annex: expressivity and inductive bias vs. Sample efficiency.
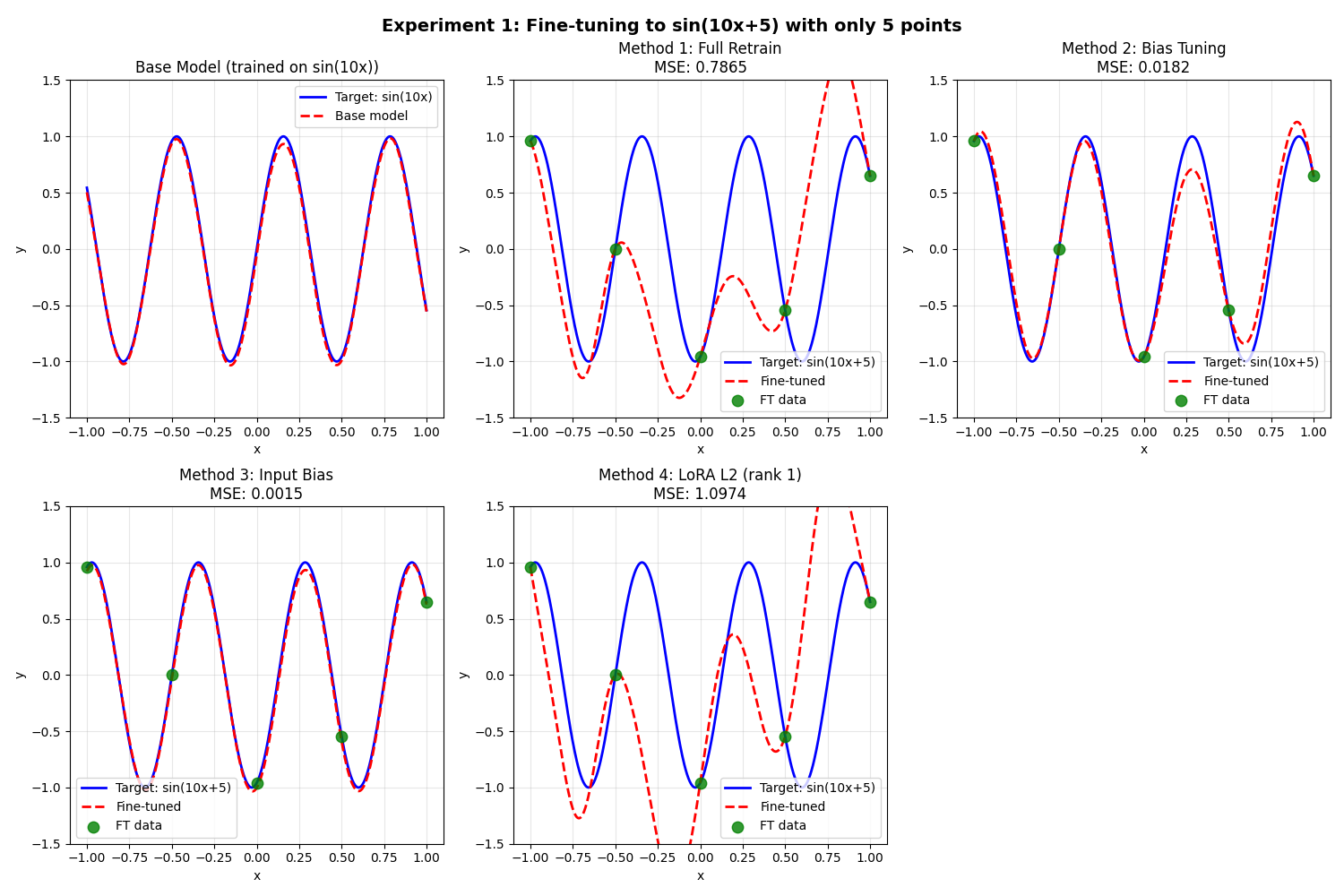
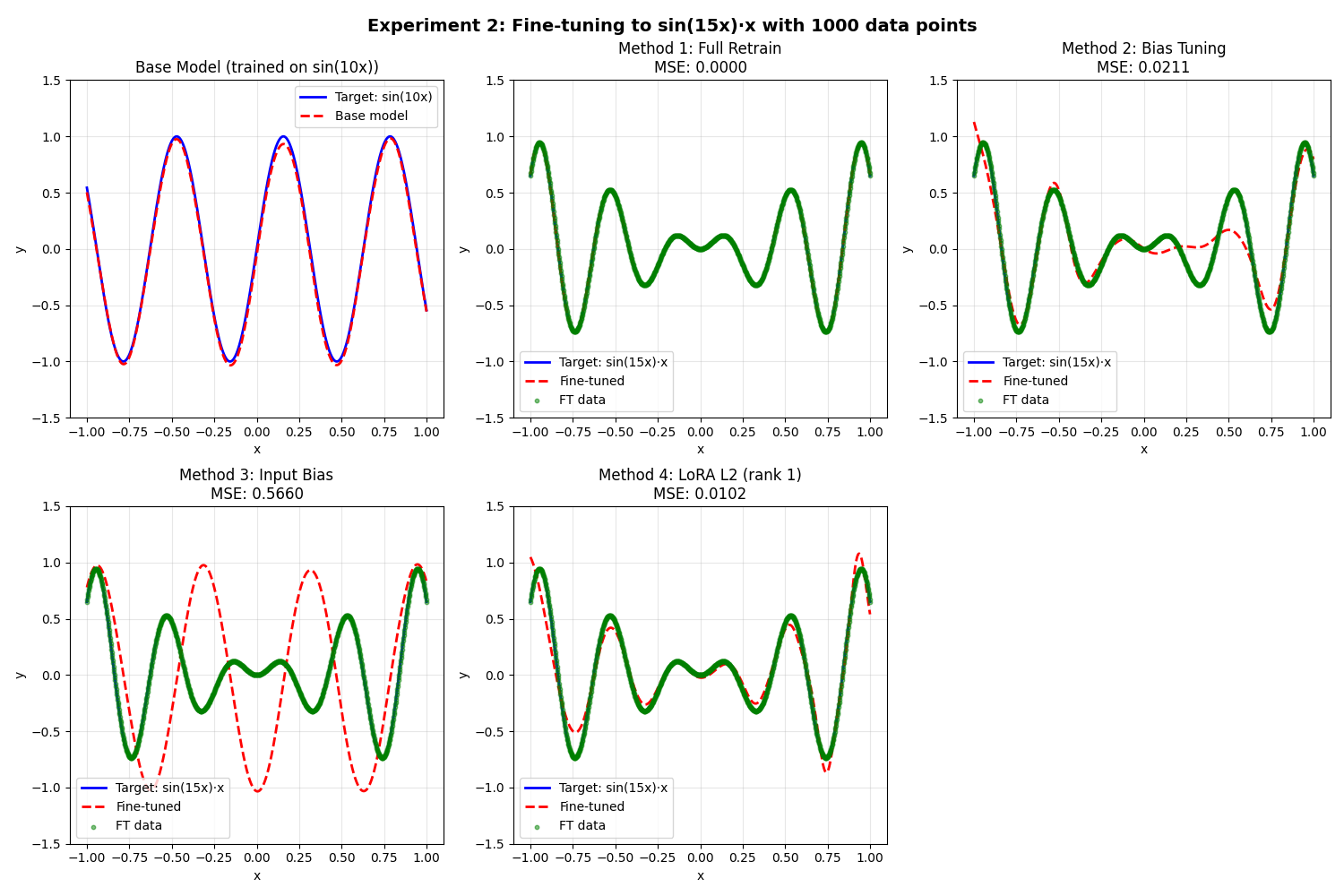
I trained a small 3-layer NN to model f(x) = sin(10x) between -1.5 and 1.5. Then, I tried to fine-tune it to model 2 different functions, using different fine-tuning methods. Most are self-explanatory. Here they are, in detail:
Full Retrain: None of the weights/biases were frozen.
Bias tuning: Weights frozen, biases are trained.
Input bias: main model is untouched, a learnable bias is added to the input.
LoRA L2 (rank 1). The second layer (dim=32) is fine-tuned using a rank-1 LoRA (so 64 params). Biases are frozen.
What’s next on this blog?
I’m currently working on something much more financially interesting: trying to predict the performance of companies based on the full text of their financial reports and websites. And pretty much all the text you can find about them.
I’m probably going to write a couple of blog posts on the matter in the near future, because I’ve made a few interesting advances in long context modeling for encoder transformers that I’d be happy to share.
Also, I’ve found a way to make encoder models much, much better at numeracy and tabular data reading without having to retrain them, which is necessary to accurately encode number-heavy financial reports.
Finally, I have to try a new sentence embedding training objective that I’ve been thinking about.
Not a proper use of the concept of addition. Couldn’t think of anything better though.
Actually, it carries -log(teacher_probability_of_actual_token) more bits of information per token. (Assuming that the absolute goal of the student model is to learn its teacher transfer function)
Indeed, prefix tokens can only steal attention from other tokens, without changing the ordering of attention scores among non-prefix tokens. At least in the first layer.